7.1. Introduction to Metadata Extraction
Once content is successfully crawled into an archival unit (AU) in a LOCKSS node, optionally with the help of hash filters and related plugin features, the AU is preserved by polling and repairing with other nodes in the network holding the same AU. If metadata extraction from preserved data is desired beyond the preservation of the data itself and the metadata database is enabled, the plugin needs to specify metadata extraction features.
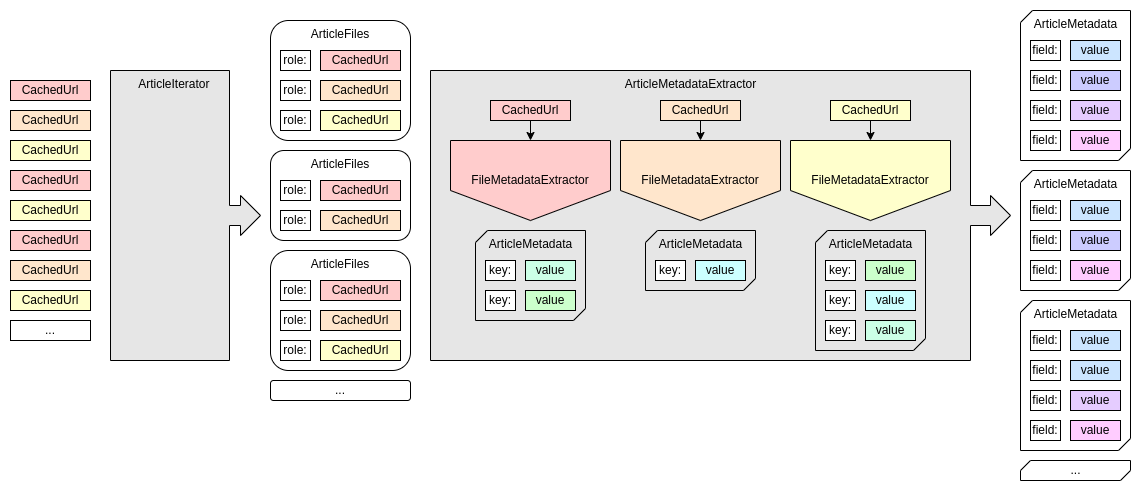
Metadata extraction relies on a trio of related concepts:
An Article Iterator groups an AU's URLs into one cluster per article ("article" in the sense of "object" or "item").
The URLs are represented internally as
org.lockss.plugin.CachedUrlobjects. The object representing an article's cluster of URLs is of typeorg.lockss.plugin.ArticleFiles, and is essentially a mapping from string roles to URLs.An article iterator is merely an object implementing
java.util.Iterator<ArticleFiles>, that comes from a factory implementing theorg.lockss.plugin.ArticleIteratorFactoryinterface.A media type-specific File Metadata Extractor parses the contents of a URL and emits any number of intermediate metadata records.
A file metadata extractor is an object implementing the
org.lockss.extractor.FileMetadataExtractorinterface and emitting metadata records of typeorg.lockss.extractor.ArticleMetadatathrough an object implementing theorg.lockss.extractor.FileMetadataExtractor.Emitterinterface. The latter is called for each (CachedUrl,ArticleFiles) pair, creating a one-to-many relationship fromCachedUrltoArticleFiles.An Article Metadata Extractor receives each article's
ArticleFilesobject, and emits any number of processed metadata records (of the same typeArticleMetadata).An article metadata extractor implements the
org.lockss.extractor.ArticleMetadataExtractorinterface and emitsArticleMetadataobjects through an object implementing theorg.lockss.extractor.ArticleMetadataExtractor.Emitterinterface. The latter is called for each (ArticleFiles,ArticleMetadata) pair, creating a one-to-many relationship fromArticleFilestoArticleMetadata.The article metadata extractor picks and chooses URLs of interest from the
ArticleFilesinstance, invokes the file metadata extractors for the corresponding media types yielding intermediateArticleMetadataobjects, and emits appropriate finalArticleMetadataobjects from them.
Although in principle there are file metadata extractors for multiple media types, a one-to-many relationship from CachedUrl to ArticleFiles in file metadata extractors, and a one-to-many relationship from ArticleFiles to ArticleMetadata in article metadata extractors, in many situations plugins derive all the metadata they need from a single media type, there is a one-to-one-to-one correspondence between a CachedUrl, ArticleFiles and ArticleMetadata triple, and the intermediate metadata records can often be emitted as final metadata records.
This process can be summarized in the following diagram: